If you’ve been following the development of BloodHound, you’ll notice that the team has been very active lately. The culmination of all this recent work is the release of BloodHound 1.4. While the changes made may seem minor, we’ve decided that it deserves being tagged with a new release number, as it fixes quite a few issues and introduces some new features which should lead to far more interesting queries and analytics down the line. These new queries are on the to-do list for the BloodHound team, and should come out in the near(ish) future. However, we felt it was important to release this update sooner rather than later to introduce users to new concepts and fix some critical bugs.
Neo4j 3.1.6 (ShortestPath Bug) Fixes
One of the most annoying issues for users was the incompatibility of the BloodHound user interface with Neo4j versions over 3.1.6. With the release of 3.1.6, Neo4j changed queries that use shortest path algorithms to fail if the start and end node was the same. As an example, the derivative local admin’s query for computer nodes resolves as follows:
MATCH (a:Computer {name:"PRIMARY.TESTLAB.LOCAL"}) WITH a MATCH (b:Computer) WITH a,b MATCH p=shortestPath(a-[r:AdminTo|MemberOf|HasSession*1..]->b) RETURN p
We specify an explicit name for node a (PRIMARY.TESTLAB.LOCAL), but don’t specify anything for node b. Because b is also a computer, and the match is unbounded, eventually b may also include a. Previously, this did not throw an error and was silently ignored. In the 1.4 update of BloodHound, all the queries in the UI have been modified to appropriately exclude the starting nodes from the second match. With this fix, many of the queries which were “broken” have started working again, particularly the Transitive Object Control query.
Object Properties Collection
If you’ve been using BloodHound for a while, you probably noticed the data entries on user and computer nodes that have been in the user interface since the very beginning.
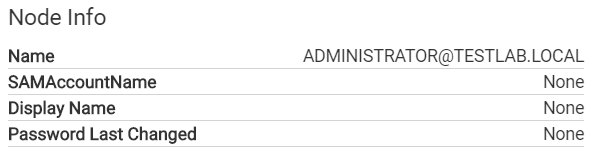
These are features that we’ve wanted to have in BloodHound for…well since the beginning. Some users even removed the features from their local branch since they were basically useless (looking at you @porterhau5). However, it always fell lower on the priority list than the other functional features we found necessary. However, with the rewrite of the ingestor, and the release of SharpHound, we finally had the luxury to easily add features to the ingestor. Those who have had a chance to read through the old PowerShell ingestor understand that it wasn’t the most maintainable of code-bases, which made adding anything fairly painful, even when you have the power of harmj0y on your side.
New Cool Stuff!
After over a year, we finally found the time to add the ability to collect properties of objects. We haven’t yet integrated all the properties we would like, but it’s certainly a start. Here’s an example for users.

And for computers.
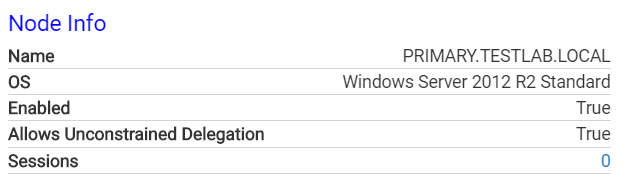
All of these properties are stored as properties of the node in the database, which means they’re fully usable in queries. As we continue to add new properties, we will index them appropriately on the UI. These new properties let you do smarter queries, such as filtering disabled users or computers out of pathfinding, or for a particularly interesting one:
MATCH (a:User {HasSPN:true}) RETURN a
A new boolean property has been added to nodes, HasSPN, which as the name implies, denotes whether a user has a ServicePrincipalName set. Those familiar with the kerberoasting technique will immediately understand why this is a powerful query. One of the biggest challenges presented during the kerberoasting process is deciding which users to focus cracking time on. With this property in BloodHound, you can quickly identify which users with SPNs will provide you with interesting rights, as well as immediately see how long ago the password was changed. Finding a high privilege account with SPNs set and a password last set 10 years ago should move that account to the top of your password cracking priority list.
The addition of the Email property can facilitate post-exploitation and re-phishing from an internal context, and collecting service principal names will allow you to quickly find users that drive, for example, MSSQL services on hosts.
Collecting Object Data
To collect the object properties for nodes, simply run SharpHound with the new -CollectionMethod ObjectProps :
Invoke-BloodHound -CollectionMethod ObjectProps
SharpHound will generate two new CSV files, user_properties.csv and computer_properties.csv. These files will upload properly in the 1.4 release of BloodHound, and populate data on all of the nodes.
The following properties are currently indexed for users:
- DisplayName (string) - The display name set in Active Directory
- Enabled (boolean) - Whether the user account is enabled (derived from the UserAccountControl property)
- PwdLastSet (int) - The epoch timestamp at which the password was last set
- LastLogon (int) - The epoch timestamp at which the user last logged on
- Sid (string) - The security identifier for the user
- SidHistory (string) - The SidHistory property if the user has one
- HasSPN (boolean) - Whether the user has a ServicePrincipalName set
- ServicePrincipalNames (array) - A list of the ServicePrincipalNames set on the user
- Email - The email set for the user in Active Directory
The following properties are currently indexed for computers:
- Enabled (boolean) - Whether the computer account is enabled
- UnconstrainedDelegation (boolean) - Whether the computer allows unconstrained delegation. Sean Metcalf (@PyroTek3) has an excellent write up on this topic here.
- PwdLastSet (int) - The epoch timestamp at which the computer password was last set
- LastLogon (int) - The epoch timestamp at which the computer last logged on
- OperatingSystem (string) - A string representing the operating system of the computer
- Sid (string) - The security identifier for the computer
Adding these properties to the computer and user nodes opens up several new possibilities for pathfinding, analytics, and statistical modelling. We now have the ability to answer new questions in the data. Some examples:
- What is the most highly privileged disabled user in my domain?
- What users haven’t logged in recently, and therefore can be excluded from our paths?
- What computers are we missing data from that have logged in since our collection started?
We’ll be adding some new queries based on these and other ideas, and we look forward to seeing what the community comes up with!
Zip Ingestion and Rewritten CSV Ingestion
One of my personal favorite features added to SharpHound is the ability to automatically compress your CSV files to a timestamped zip file. Effectively, this means you can have zip files from different runs that represent discrete data points in time for your network.

This feature significantly increases the speed at which you can download your data from remote hosts, not to mention adds convenience to the process. We decided to add even more convenience, in the form of full zip file support for the CSV ingestion in the user interface. When you choose a zip file, the files will be unzipped to your user’s temporary directory, processed normally, and then deleted. This essentially allows you to maintain points in time for your network without having to maintain multiple databases. Simply clear your current database, and upload the zip file that corresponds with the point in time you collected data.
Additionally, the old CSV ingestion logic was prone to strange issues, due to some issues with the parsing library we used, particularly the fact that NodeJS streams were not natively supported. We switched to the wonderful fast-csv library, which supports features we were looking for, and as a result the parsing logic should be more robust and less prone to errors. Additionally, we discovered that some rows were not even being properly processed due to the previous library suppressing errors. The collection logic has been correspondingly fixed in SharpHound to ensure that fields that might have commas are properly quoted.
DcSync Edges
DcSync is one of the most powerful tools available in any tester’s arsenal, allowing you to quickly extract passwords for specific accounts from the domain, provided you have the appropriate rights. While most of the time having a member of Domain Admins is the barrier to DcSync, the rights necessary to perform the action are actually explicitly defined in Access Control Entries (ACEs) within the Discretionary Access Control List (DACL). Any principal which has the two following ACEs on the domain object can DcSync: DS-Replication-Get-Changes and DS-Replication-Get-Changes-All.
SharpHound will now properly resolve principals with both those rights and present you with a new edge in the user interface.

In the future, we would love to be able to properly resolve this right to other nodes in the appropriate domain in order to properly integrate it into pathfinding. However, for now, the list of users who can DcSync for a particular domain is still valuable information, and may identify unexpected users that can be used to escalate quickly. There may be other conditions that allow DcSync rights, which we will continue to add as we find them!
SharpHound Updates
The open beta of SharpHound started not too long ago, and we’ve been hard at work fixing issues we find and adding more functionality to it whenever we can. There have been many minor fixes, as well as some bigger ones that fix long running issues. Outside of the addition of ObjectProperties collection method, which is the focus of the 1.4 release, here are some of the highlights of fixes and changes made in the last few weeks.
REST API Ingestion Fixes
The REST API is one of the most underused features in BloodHound, and a large part of that is convenience. Using CSVs is simple, and up until now, significantly faster. However, there are still a few users who use the REST API to import their data, and we wouldn’t want to leave them in the dark. Thanks to testing from users in the BloodHound slack channel, many of the issues with the REST API ingestion were identified and fixed. To our knowledge, the speed of ingestion should be completely comparable to importing from the UI.
Deduplication of CSV Files
Each entry in the CSV file is another network request that is made during ingestion. Duplicate nodes in data result in slowing down the overall import process without any benefit. SharpHound will now run a pass over each CSV file at the end of operation that will strip duplicate entries out. This helps speed up the data import process and lowers the size of files.
Local Admin Optimization
One of the hardest parts of developing SharpHound is the lack of test environments. Thanks to beta testers, several issues were identified in the local admin enumeration segment of the collection, which have been fixed. In particular, several hangs were found in the code which was causing SharpHound to be unable to finish. Hopefully, they have been resolved. Additionally, some edge cases were identified that were causing the local admin function to take upwards of 20 seconds on hosts to return. Fixing those issues should result in another speedup in the enumeration process.
Session Enumeration DNS Resolution Fallback
Session enumeration is easily the part of collection that requires the most guesswork. There are many factors that come into play that makes getting accurate data difficult, and we’re always trying to ensure that the data that comes back is the best possible. One of the issues with session collection is the resolution of hosts where sessions originate from. Because the APIs used to collect session information return IP addresses, hosts that did not have a PTR set would result in an IP address showing in the data. We’ve taken steps to resolve this by implementing some extra fallbacks to attempt to get better data and hostnames in more cases.
Wrap Up
The combination of BloodHound and SharpHound together has opened up many new possibilities for analytics and data collection that should lead to some very interesting analytics and queries. The addition of the new object properties should lead to a whole slew of new analytics that were not possible previously, and should allow both defenders and attackers to gain even more valuable insights into their datasets. We have several new queries coming down the pipeline to allow quick analysis without any extra work, and we look forward to seeing new stuff the community comes up with! The 1.4 release of BloodHound can be found here with pre-compiled binaries, or as always you can compile it yourself. SharpHound can now be found in the main repository alongside the original Powershell based ingestor here.
As usual, feel free to join us any time in the BloodHound Slack Channel. The link will allow you to get an invite, and join our active community with over 650 users. It’s also the most direct way to get in touch with us for BloodHound issues. We look forward to hearing from any new users and hopefully making BloodHound better for everyone!